Gradient (matematyka)
 | Ten artykuł dotyczy pojęcia matematycznego. Zobacz też: inne znaczenia. |
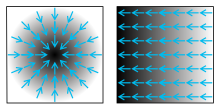
Gradient – pole wektorowe wskazujące kierunki najszybszych wzrostów wartości danego pola skalarnego w poszczególnych punktach[1], przy czym moduł („długość”) każdego wektora jest równy szybkości wzrostu pola skalarnego w kierunku największego wzrostu.
Gradientem nazywa się również pojedynczy wektor wskazujący kierunek i szybkość wzrostu wspomnianego pola skalarnego w danym punkcie; wektor przeciwny do gradientu (oraz odpowiadające mu przeciwne do gradientowego pole wektorowe) nazywa się często antygradientem. Wyrażenie „zgodnie z gradientem” należy rozumieć jako „zgodnie z kierunkiem najszybszego wzrostu”.
Gradient to wreszcie nazwa operatora różniczkowego przekształcającego pole skalarne w opisane wyżej pole wektorowe (w powyższych znaczeniach gradient jest obrazem wspomnianego operatora, odpowiednio całej dziedziny i pojedynczego punktu). Uogólnieniem gradientu na funkcje przestrzeni euklidesowej w inną jest macierz Jacobiego. Jest ona macierzą przekształcenia liniowego znanego jako pochodna zupełna, dlatego za dalej idące uogólnienia (na funkcje między przestrzeniami Banacha) można uważać pochodną Gâteaux, a przy dodatkowych założeniach: pochodną Frécheta.
Intuicja
Intuicyjnie gradient jest wektorem, którego zwrot wskazuje kierunek najszybszego wzrostu wartości funkcji, a którego długość („moduł”) odpowiada wzrostowi wartości tej funkcji na jednostkę długości.
Wprowadzenie
Przykładem może być pokój, w którym temperatura opisana jest polem skalarnym Tak więc w każdym punkcie temperatura wynosi (zakładamy, że nie zmienia się ona w czasie). Wówczas w każdym punkcie pokoju gradient w tym punkcie pokazuje kierunek (wraz ze zwrotem), w którym temperatura rośnie najszybciej. Moduł gradientu wskazuje jak szybko rośnie temperatura w tym kierunku.




Innym przykładem może być powierzchnia ze wzgórzem, dla której oznacza wysokość nad poziomem morza w punkcie Gradientem w punkcie jest wektor wskazujący kierunek największego pochylenia w tym punkcie. Miara tego pochylenia jest dana jako moduł wektora gradientu.




Dzięki iloczynowi skalarnemu gradient można wykorzystać do mierzenia nie tylko tego, jak pole skalarne zmienia się w kierunku największej zmiany, lecz także w innych kierunkach. Niech w przykładzie ze wzgórzem największe pochylenie zbocza wynosi 40%. Jeśli droga biegnie prosto pod górę, to największe pochylenie drogi również będzie wynosić 40%. Jeśli jednak droga biegnie wokół wzgórza pod pewnym kątem (względem wektora gradientu), to będzie miała mniejsze nachylenie. Przykładowo jeśli kąt między drogą a kierunkiem w górę, rzutowany na płaszczyznę poziomą, wynosi 60°, to największe nachylenie wzdłuż drogi będzie wynosić 20%, co jest równe 40% razy cosinus 60°.
Ta obserwacja może być wyrażona matematycznie w następujący sposób. Jeśli funkcja wysokości terenu jest różniczkowalna, to gradient funkcji pomnożony skalarnie przez wektor jednostkowy daje pochylenie terenu w kierunku tego wektora. Dokładniej, jeśli jest różniczkowalna, to iloczyn skalarny gradientu przez dany wektor jednostkowy jest równy pochodnej kierunkowej w kierunku tego wektora jednostkowego.
Podobnie obrazuje się zmianę innych wielkości fizycznych takich jak: stężenie, współczynnik pH, gęstości ładunku elektrycznego, jasność, kolor itp. w określonej przestrzeni.
Definicja


Gradient (lub gradientowe pole wektorowe) funkcji skalarnej oznaczany gdzie (nabla) to wektorowy operator różniczkowy nazywany nabla. Innym oznaczeniem gradientu jest





W układzie współrzędnych kartezjańskich gradient jest wektorem, którego składowe są pochodnymi cząstkowymi funkcji Gradient definiuje się jako pewne pole wektorowe. W układzie współrzędnych kartezjańskich składowe gradientu funkcji są pochodnymi cząstkowymi tej funkcji, tzn.

![{\displaystyle \nabla f=\left[{\frac {\partial f}{\partial x_{1}}},\dots ,{\frac {\partial f}{\partial x_{n}}}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de517acf742ec13d2a2acc56837ebfdaa3555177)
Gradient jest wektorem kolumnowym, jednak bywa zapisywany jako wektor wierszowy. Jeżeli funkcja zależy także od parametru takiego jak czas, to zwykle gradient oznacza wtedy wektor jej pochodnych przestrzennych.
Gradient funkcji wektorowej to


lub też transpozycja macierzy Jacobiego

Jest to tensor drugiego rzędu.
Ogólniej gradient może być zdefiniowany za pomocą pochodnej zewnętrznej:

Symbole oraz oznaczają tutaj izomorfizmy muzyczne.


Postać w trójwymiarowej przestrzeni współrzędnych
Postać gradientu zależy od użytego układu współrzędnych i wymiaru przestrzeni. Np. w przestrzeni trójwymiarowej gradient wyraża się przez trzy współrzędne następująco:
![{\displaystyle \nabla f(x,y,z)=\left[{\frac {\partial f}{\partial x}},{\frac {\partial f}{\partial y}},{\frac {\partial f}{\partial z}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b522038edcc0716bc3f0f743c94159fedbbd20f4)
![{\displaystyle \nabla f(r,\theta ,z)=\left[{\frac {\partial f}{\partial r}},{\frac {1}{r}}{\frac {\partial f}{\partial \theta }},{\frac {\partial f}{\partial z}}\right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1f1d3033ecdc55fb8264845b57f82aac0933f1e)
![{\displaystyle \nabla f(r,\theta ,\varphi )=\left[{\frac {\partial f}{\partial r}},{\frac {1}{r}}{\frac {\partial f}{\partial \theta }},{\frac {1}{r\sin \theta }}{\frac {\partial f}{\partial \varphi }}\right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e034e39d44142363b37a943cad8171ea9a83d4c)
Jeśli oznaczyć przez wersory osi układu współrzędnych kartezjańskich, to gradient można zadać jako


Podobnie jest dla innych układów współrzędnych.
Przykład
Gradientem funkcji

zadanej we współrzędnych kartezjańskich jest wektor

![{\displaystyle \nabla f=\left[{\frac {\partial f}{\partial x}},{\frac {\partial f}{\partial y}},{\frac {\partial f}{\partial z}}\right]=[2,6y,-\cos z].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/35b73f018f390c06c6d6a3a79654a803e0144a20)
Związek z pochodną i różniczką
Przybliżenie liniowe funkcji
Gradient funkcji przestrzeni euklidesowej w prostą euklidesową w dowolnym punkcie należącym do charakteryzuje najlepsze przybliżenie liniowe w punkcie Rozumie się przez to





dla bliskiego gdzie oznacza gradient obliczony w punkcie a kropka to iloczyn skalarny na Równanie to jest równoważne dwóm pierwszym wyrazom rozwinięcia szeregu Taylora wielu zmiennych dla w punkcie



Różniczka i pochodna (zewnętrzna)
Najlepszym przybliżeniem liniowym funkcji w punkcie należącym do jest przekształcenie liniowe oznaczane często lub i nazywane różniczką bądź pochodną zupełną funkcji w punkcie Stąd gradient związany jest różniczką następującym wzorem






dla dowolnego Funkcja która przekształca na nazywa się różniczką lub pochodną zewnętrzną Jest to przykład 1-formy różniczkowej.



Jeśli postrzegać jako przestrzeń wektorów kolumnowych o składowych rzeczywistych, to można uważać za wektor wierszowy


![{\displaystyle \operatorname {d} f=\left[{\frac {\partial f}{\partial x_{1}}},\dots ,{\frac {\partial f}{\partial x_{n}}}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c33cab27da1c54648100a235f44ec13a010dc568)
tak, iż jest dana poprzez mnożenie macierzy. Gradient jest wówczas odpowiadającym mu wektorem kolumnowym, tzn.


Gradient jako pochodna
| | Tę sekcję należy dopracować: gradient w istocie to pochodne cząstkowe/kierunkowe, czyli pochodna Gâteaux (słaba); pochodna Frécheta (silna) wymaga dodatkowych założeń. Dokładniejsze informacje o tym, co należy poprawić, być może znajdują się w dyskusji tej sekcji. Po wyeliminowaniu niedoskonałości należy usunąć szablon {{Dopracować}} z tej sekcji. |
Niech będzie zbiorem otwartym w Jeśli funkcja jest różniczkowalna (w sensie Frécheta), to różniczką jest pochodna Frécheta Stąd jest funkcją z w taką, że




gdzie oznacza iloczyn skalarny.

Stąd gradient spełnia standardowe własności pochodnej:
- Liniowość
- Gradient jest liniowy w tym sensie, iż jeżeli i są dwiema funkcjami o wartościach rzeczywistych różniczkowalnymi w punkcie zaś i są dwoma skalarami (stałymi rzeczywistymi), to kombinacja liniowa jest różniczkowalna w i co więcej:







- Reguła iloczynu
- Niech i są dwiema funkcjami o wartościach rzeczywistych różniczkowalnymi w punkcie wówczas reguła iloczynu zapewnia, że iloczyn funkcji i jest różniczkowalny w oraz


- Reguła łańcuchowa
- Niech będzie funkcją o wartościach rzeczywistych określoną na podzbiorze przestrzeni różniczkowalną w punkcie Istnieją dwie postaci reguły łańcuchowej związanej z gradientem. Wpierw niech oznacza krzywą parametryczną, tj. funkcję odwzorowującą podzbiór w Jeśli jest różniczkowalna w punkcie takim, że to
- Ogólniej, jeśli jest to prawdziwa jest równość:
- gdzie oznacza macierz Jacobiego, zaś oznacza transpozycję macierzy.
- Drugą postać reguły łańcuchowej można przedstawić następująco: niech będzie funkcją o wartościach rzeczywistych określoną na podzbiorze prostej przy czym jest różniczkowalna w punkcie Wówczas



















Własności przekształceń
Choć gradient jest zdefiniowany za pomocą współrzędnych, to jest on kontrawariantny ze względu na przekształcenie współrzędnych za pomocą macierzy ortogonalnej. Jest to prawda w tym sensie, że jeżeli jest macierzą ortogonalną, to


co wynika z opisanej wyżej reguły łańcuchowej. Wektor zachowujący się w ten sposób nazywa się wektorem kontrawariantnym, gradient jest zatem szczególnym rodzajem tensora.
Różniczka jest naturalniejsza od gradientu, gdyż jest niezmiennicza na wszystkie przekształcenia współrzędnych (dyfeomorfizmy), podczas gdy gradient jest niezmienniczy tylko na przekztałcenia ortogonalne (ze względu na jawne użycie iloczynu skalarnego w definicji). Z tego powodu często rozmywa się różnicę między tymi dwoma pojęciami korzystając z pojęcia wektorów kowariantnych i kontrawariantnych. Z tego punktu widzenia składowe gradientu przekształcane są kowariantnie przy zmianie współrzędnych, dlatego mówi się o kowariantnym polu wektorowym, podczas gdy składowe pola wektorowego w zwykłym sensie zmieniają się kontrawariantnie. W języku tym gradient jest więc różniczką, jako że kowariantne pole wektorowe jest tym samym, co 1-forma różniczkowa[a].
Uogólnienie na rozmaitości riemannowskie
 Zobacz też: rozmaitość riemannowska.
Zobacz też: rozmaitość riemannowska.

Dla dowolnej funkcji gładkiej określonej na rozmaitości riemannowskiej gradient to pole wektorowe takie, że dla dowolnego pola wektorowego zachodzi


- tzn.


gdzie to iloczyn wewnętrzny wektorów stycznych w punkcie wyznaczony przez metrykę symbol oznacza gradient obliczony w punkcie zaś oznaczane czasami jest funkcją, która każdemu punktowi przyporządkowuje pochodną kierunkową w kierunku obliczoną w punkcie









Innymi słowy opisana za pomocą mapy z otwartego podzbioru w podzbiór otwarty jest dana wzorem:




gdzie oznacza -tą składową w tej mapie.


Tak więc lokalnie gradient przyjmuje postać:

Uogólniając przypadek gradient funkcji jest związany z pochodną zewnętrzną, gdyż gdzie to pochodna w punkcie Dokładniej, gradient jest polem wektorowym związanym z 1-formą różniczkową za pomocą izomorfizmu muzycznego (nazywanego „krzyżykiem”) określonego za pomocą metryki Związek między pochodną zewnętrzną a gradientem funkcji jest przypadkiem szczególnym powyższego, gdy metryka jest płaską metryką daną za pomocą (euklidesowego) iloczynu skalarnego.





Dalsze własności i zastosowania
Poziomice
- Zobacz też: poziomica (matematyka).
Dla funkcji określonej w punkcie można rozważać powierzchnię przez niego przechodzącą, w punktach której funkcja przyjmuje wszędzie tę samą wartość. Powierzchnię taką nazywa się wówczas powierzchnią poziomicy.

Jeśli pochodne cząstkowe są ciągłe, to iloczyn skalarny gradientu w punkcie i wektora daje pochodną kierunkową w punkcie wzdłuż Wynika stąd, że w tym przypadku gradient jest ortogonalny do poziomic Przykładowo powierzchnia poziomicy w przestrzeni trójwymiarowej jest określona równaniem postaci Gradient jest wtedy wektorem normalnym do powierzchni.





Ogólniej, dowolna hiperpowierzchnia zanurzona w rozmaitości riemannowskiej może być opisana równaniem postaci gdzie nigdzie nie znika. Gradient jest wtedy normalny do tej hiperpowierzchni.


Nauki przyrodnicze
- W niektórych szybko przebiegających reakcjach chemicznych zachodzących na granicy faz zachodzi zjawisko gradientowego stężenia substratów w objętości. Stwierdzenie to oznacza, że blisko granicy faz, gdzie przebiega właściwa reakcja stężenie produktów jest najwyższe, zaś czym dalej od tej granicy stężenie to spada. Zjawisko takie zachodzi np. przy elektrolizie.
- W przypadku polimerów możliwe jest otrzymywanie tzw. kopolimerów gradientowych, w których na jednym końcu polimeru występuje więcej jednego, a na przeciwległym drugiego meru.
- W meteorologii fragment opisu stanu atmosfery „W niezbyt grubej warstwie –81 m, różnica temperatury wynosiła aż 8,5 °C, tj. średnio ponad jeden stopień na 10 m wysokości. Tak duże ujemne, pionowe gradienty temperatury są rzadkością”.
- W fizyce gradientem energii potencjalnej jest siła, a potencjału (np. elektrycznego, grawitacyjnego) jest natężenie tego pola.
- W optymalizacji występują metody umożliwiające wyznaczenie ekstremów funkcji wielu zmiennych: metoda gradientu prostego, metoda gradientu sprzężonego, metoda najszybszego spadku, metoda Newtona, algorytm Levenberga-Marquardta.
Uwagi
- ↑ Niestety, ten dezorientujący język wprowadza dalsze zamieszanie ze względu na różne konwencje. Choć składowe 1-formy różniczkowej zmieniają się kowariantnie ze względu na przekształcenia współrzędnych, to same 1-formy różniczkowe zmieniają się kontrawariatnie (poprzez pullback) ze względu na dyfeomorfizmy. Z tego powodu o 1-formach różniczkowych mówi się czasami, że są nie kowariantne, a kontrawariantne i wtedy pola wektorowe są kowariantne, nie zaś kontrawariantne.
Przypisy
- ↑ gradient, [w:] Encyklopedia PWN [dostęp 2021-10-02] .
Bibliografia
- Theresa M. Korn, Granino Arthur Korn: Mathematical Handbook for Scientists and Engineers: Definitions, Theorems, and Formulas for Reference and Review. Nowy Jork: Dover Publications, 2000, s. 157–160. ISBN 0-486-41147-8. OCLC 43864234.
- H.M. Schey: Div, Grad, Curl, and All That. Wyd. II. W. W. Norton, 1992. ISBN 0-393-96251-2. OCLC 25048561.
Linki zewnętrzne
 | Zobacz hasło gradient w Wikisłowniku |
- L.P. Kuptsov: Gradient. Michiel Hazewinkel (red.). w: Encyclopaedia of Mathematics Kluwer Academic Publishers, 2001. ISBN 978-1556080104. (ang.).
- Eric W.E.W. Weisstein Eric W.E.W., Gradient, [w:] MathWorld, Wolfram Research (ang.).
- p
- d
- e

Kontrola autorytatywna (wyrażenie matematyczne):
- GND: 4323954-7
- Britannica: topic/gradient-mathematics
- Treccani: gradiente
- DSDE: gradient










